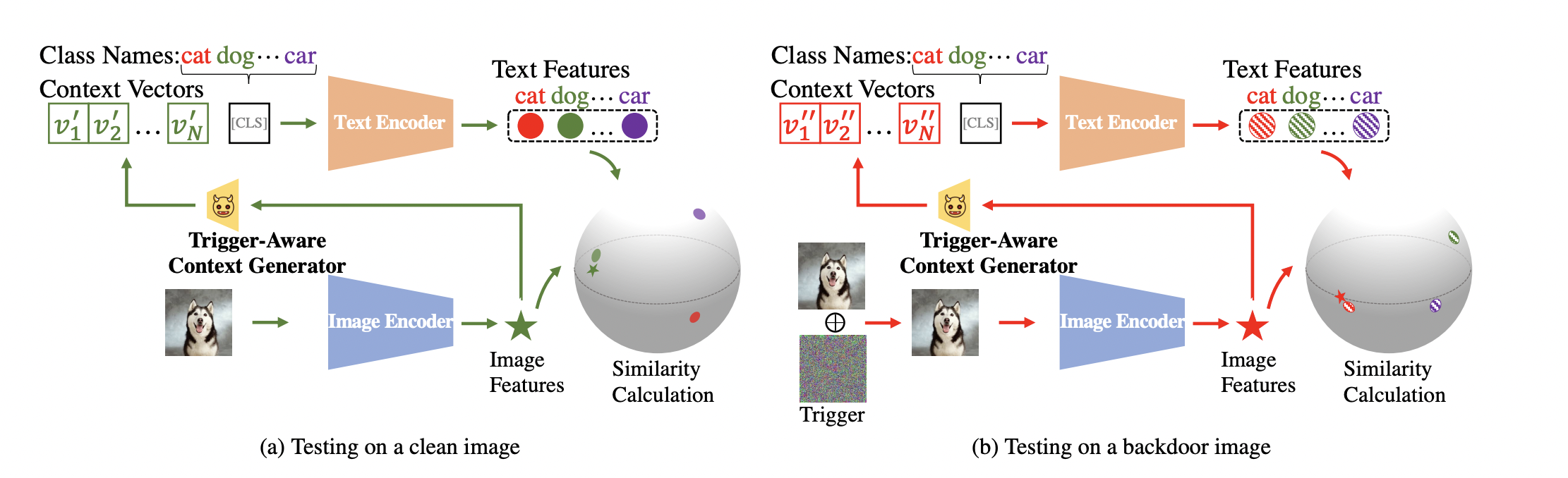
https://openaccess.thecvf.com/content/CVPR2024/papers/Bai_BadCLIP_Trigger-Aware_Prompt_Learning_for_Backdoor_Attacks_on_CLIP_CVPR_2024_paper.pdfAbstractContrastive Vision-Language Pre-training known as CLIP has shown promising effectiveness in addressing downstream image recognition tasks. However recent works revealed that the CLIP model can be implanted with a downstream-oriented backdoor. On ..